PDF Publication Title:
Text from PDF Page: 168
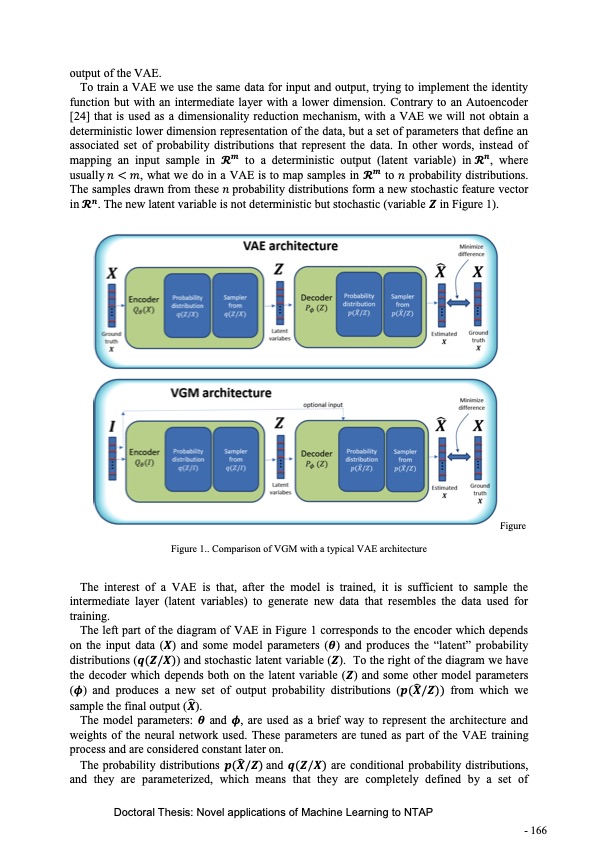
output of the VAE. To train a VAE we use the same data for input and output, trying to implement the identity function but with an intermediate layer with a lower dimension. Contrary to an Autoencoder [24] that is used as a dimensionality reduction mechanism, with a VAE we will not obtain a deterministic lower dimension representation of the data, but a set of parameters that define an associated set of probability distributions that represent the data. In other words, instead of mapping an input sample in 𝓡𝒎 to a deterministic output (latent variable) in𝓡𝒏, where usually𝑛 < 𝑚, what we do in a VAE is to map samples in 𝓡𝒎 to 𝑛 probability distributions. The samples drawn from these 𝑛probability distributions form a new stochastic feature vector in𝓡𝒏. The new latent variable is not deterministic but stochastic (variable 𝒁 in Figure 1). Figure Figure 1.. Comparison of VGM with a typical VAE architecture The interest of a VAE is that, after the model is trained, it is sufficient to sample the intermediate layer (latent variables) to generate new data that resembles the data used for training. The left part of the diagram of VAE in Figure 1 corresponds to the encoder which depends on the input data (𝑿) and some model parameters (𝜽) and produces the “latent” probability distributions (𝒒(𝒁/𝑿)) and stochastic latent variable (𝒁). To the right of the diagram we have the decoder which depends both on the latent variable (𝒁) and some other model parameters ̂ (𝝓) and produces a new set of output probability distributions (𝒑(𝑿/𝒁)) from which we ̂ sample the final output (𝑿). The model parameters: 𝜽 and 𝝓, are used as a brief way to represent the architecture and weights of the neural network used. These parameters are tuned as part of the VAE training process and are considered constant later on. ̂ The probability distributions 𝒑(𝑿/𝒁)and 𝒒(𝒁/𝑿) are conditional probability distributions, and they are parameterized, which means that they are completely defined by a set of Doctoral Thesis: Novel applications of Machine Learning to NTAP - 166PDF Image | Novel applications of Machine Learning to Network Traffic Analysis
PDF Search Title:
Novel applications of Machine Learning to Network Traffic AnalysisOriginal File Name Searched:
456453_1175348.pdfDIY PDF Search: Google It | Yahoo | Bing
Cruise Ship Reviews | Luxury Resort | Jet | Yacht | and Travel Tech More Info
Cruising Review Topics and Articles More Info
Software based on Filemaker for the travel industry More Info
The Burgenstock Resort: Reviews on CruisingReview website... More Info
Resort Reviews: World Class resorts... More Info
The Riffelalp Resort: Reviews on CruisingReview website... More Info
| CONTACT TEL: 608-238-6001 Email: greg@cruisingreview.com | RSS | AMP |