PDF Publication Title:
Text from PDF Page: 176
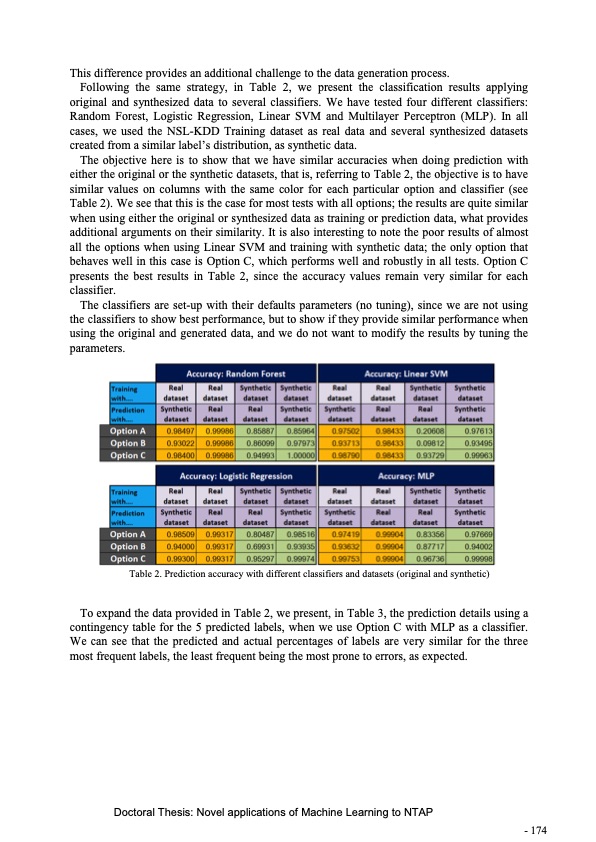
This difference provides an additional challenge to the data generation process. Following the same strategy, in Table 2, we present the classification results applying original and synthesized data to several classifiers. We have tested four different classifiers: Random Forest, Logistic Regression, Linear SVM and Multilayer Perceptron (MLP). In all cases, we used the NSL-KDD Training dataset as real data and several synthesized datasets created from a similar label’s distribution, as synthetic data. The objective here is to show that we have similar accuracies when doing prediction with either the original or the synthetic datasets, that is, referring to Table 2, the objective is to have similar values on columns with the same color for each particular option and classifier (see Table 2). We see that this is the case for most tests with all options; the results are quite similar when using either the original or synthesized data as training or prediction data, what provides additional arguments on their similarity. It is also interesting to note the poor results of almost all the options when using Linear SVM and training with synthetic data; the only option that behaves well in this case is Option C, which performs well and robustly in all tests. Option C presents the best results in Table 2, since the accuracy values remain very similar for each classifier. The classifiers are set-up with their defaults parameters (no tuning), since we are not using the classifiers to show best performance, but to show if they provide similar performance when using the original and generated data, and we do not want to modify the results by tuning the parameters. Table 2. Prediction accuracy with different classifiers and datasets (original and synthetic) To expand the data provided in Table 2, we present, in Table 3, the prediction details using a contingency table for the 5 predicted labels, when we use Option C with MLP as a classifier. We can see that the predicted and actual percentages of labels are very similar for the three most frequent labels, the least frequent being the most prone to errors, as expected. Doctoral Thesis: Novel applications of Machine Learning to NTAP - 174PDF Image | Novel applications of Machine Learning to Network Traffic Analysis
PDF Search Title:
Novel applications of Machine Learning to Network Traffic AnalysisOriginal File Name Searched:
456453_1175348.pdfDIY PDF Search: Google It | Yahoo | Bing
Cruise Ship Reviews | Luxury Resort | Jet | Yacht | and Travel Tech More Info
Cruising Review Topics and Articles More Info
Software based on Filemaker for the travel industry More Info
The Burgenstock Resort: Reviews on CruisingReview website... More Info
Resort Reviews: World Class resorts... More Info
The Riffelalp Resort: Reviews on CruisingReview website... More Info
| CONTACT TEL: 608-238-6001 Email: greg@cruisingreview.com | RSS | AMP |