PDF Publication Title:
Text from PDF Page: 178
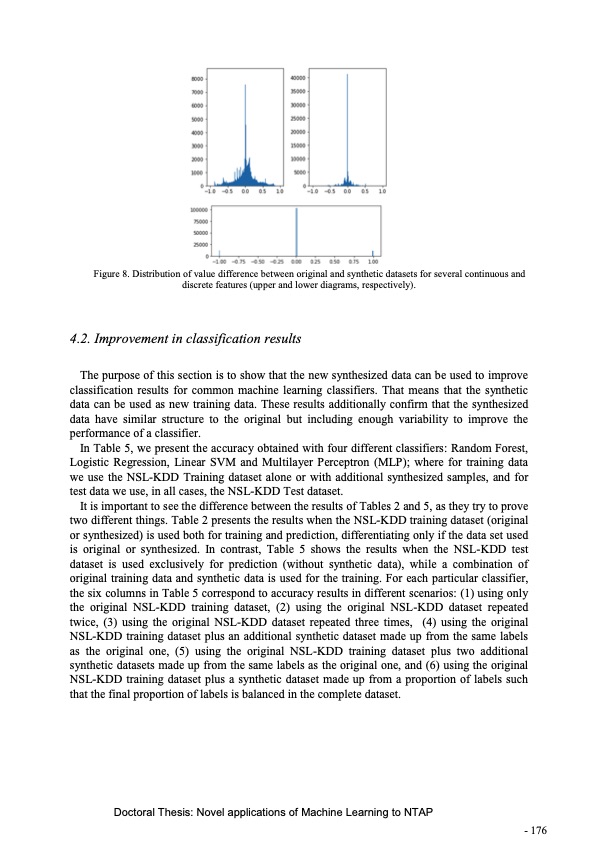
Figure 8. Distribution of value difference between original and synthetic datasets for several continuous and discrete features (upper and lower diagrams, respectively). 4.2. Improvement in classification results The purpose of this section is to show that the new synthesized data can be used to improve classification results for common machine learning classifiers. That means that the synthetic data can be used as new training data. These results additionally confirm that the synthesized data have similar structure to the original but including enough variability to improve the performance of a classifier. In Table 5, we present the accuracy obtained with four different classifiers: Random Forest, Logistic Regression, Linear SVM and Multilayer Perceptron (MLP); where for training data we use the NSL-KDD Training dataset alone or with additional synthesized samples, and for test data we use, in all cases, the NSL-KDD Test dataset. It is important to see the difference between the results of Tables 2 and 5, as they try to prove two different things. Table 2 presents the results when the NSL-KDD training dataset (original or synthesized) is used both for training and prediction, differentiating only if the data set used is original or synthesized. In contrast, Table 5 shows the results when the NSL-KDD test dataset is used exclusively for prediction (without synthetic data), while a combination of original training data and synthetic data is used for the training. For each particular classifier, the six columns in Table 5 correspond to accuracy results in different scenarios: (1) using only the original NSL-KDD training dataset, (2) using the original NSL-KDD dataset repeated twice, (3) using the original NSL-KDD dataset repeated three times, (4) using the original NSL-KDD training dataset plus an additional synthetic dataset made up from the same labels as the original one, (5) using the original NSL-KDD training dataset plus two additional synthetic datasets made up from the same labels as the original one, and (6) using the original NSL-KDD training dataset plus a synthetic dataset made up from a proportion of labels such that the final proportion of labels is balanced in the complete dataset. Doctoral Thesis: Novel applications of Machine Learning to NTAP - 176PDF Image | Novel applications of Machine Learning to Network Traffic Analysis
PDF Search Title:
Novel applications of Machine Learning to Network Traffic AnalysisOriginal File Name Searched:
456453_1175348.pdfDIY PDF Search: Google It | Yahoo | Bing
Cruise Ship Reviews | Luxury Resort | Jet | Yacht | and Travel Tech More Info
Cruising Review Topics and Articles More Info
Software based on Filemaker for the travel industry More Info
The Burgenstock Resort: Reviews on CruisingReview website... More Info
Resort Reviews: World Class resorts... More Info
The Riffelalp Resort: Reviews on CruisingReview website... More Info
| CONTACT TEL: 608-238-6001 Email: greg@cruisingreview.com | RSS | AMP |