PDF Publication Title:
Text from PDF Page: 041
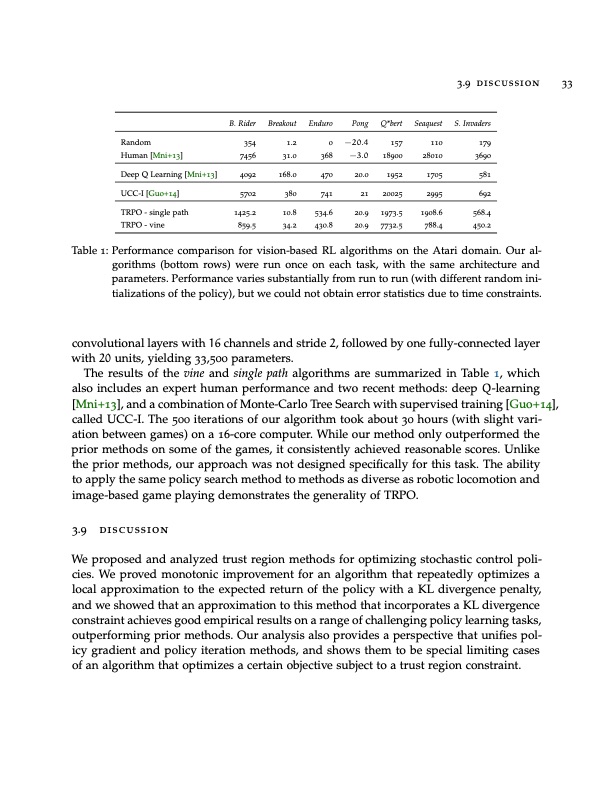
B. Rider Random 354 Breakout Enduro Pong 1.2 0 −20.4 31.0 368 −3.0 168.0 470 20.0 380 741 21 10.8 534.6 20.9 34.2 430.8 20.9 Q*bert 157 18900 1952 20025 1973.5 7732.5 Seaquest 110 28010 1705 2995 1908.6 788.4 3.9 discussion 33 S. Invaders 179 3690 581 692 568.4 450.2 Human [Mni+13] Deep Q Learning [Mni+13] UCC-I [Guo+14] TRPO - single path TRPO - vine 7456 4092 5702 1425.2 859.5 Table 1: Performance comparison for vision-based RL algorithms on the Atari domain. Our al- gorithms (bottom rows) were run once on each task, with the same architecture and parameters. Performance varies substantially from run to run (with different random ini- tializations of the policy), but we could not obtain error statistics due to time constraints. convolutional layers with 16 channels and stride 2, followed by one fully-connected layer with 20 units, yielding 33,500 parameters. The results of the vine and single path algorithms are summarized in Table 1, which also includes an expert human performance and two recent methods: deep Q-learning [Mni+13], and a combination of Monte-Carlo Tree Search with supervised training [Guo+14], called UCC-I. The 500 iterations of our algorithm took about 30 hours (with slight vari- ation between games) on a 16-core computer. While our method only outperformed the prior methods on some of the games, it consistently achieved reasonable scores. Unlike the prior methods, our approach was not designed specifically for this task. The ability to apply the same policy search method to methods as diverse as robotic locomotion and image-based game playing demonstrates the generality of TRPO. 3.9 discussion We proposed and analyzed trust region methods for optimizing stochastic control poli- cies. We proved monotonic improvement for an algorithm that repeatedly optimizes a local approximation to the expected return of the policy with a KL divergence penalty, and we showed that an approximation to this method that incorporates a KL divergence constraint achieves good empirical results on a range of challenging policy learning tasks, outperforming prior methods. Our analysis also provides a perspective that unifies pol- icy gradient and policy iteration methods, and shows them to be special limiting cases of an algorithm that optimizes a certain objective subject to a trust region constraint.PDF Image | OPTIMIZING EXPECTATIONS: FROM DEEP REINFORCEMENT LEARNING TO STOCHASTIC COMPUTATION GRAPHS
PDF Search Title:
OPTIMIZING EXPECTATIONS: FROM DEEP REINFORCEMENT LEARNING TO STOCHASTIC COMPUTATION GRAPHSOriginal File Name Searched:
thesis-optimizing-deep-learning.pdfDIY PDF Search: Google It | Yahoo | Bing
Cruise Ship Reviews | Luxury Resort | Jet | Yacht | and Travel Tech More Info
Cruising Review Topics and Articles More Info
Software based on Filemaker for the travel industry More Info
The Burgenstock Resort: Reviews on CruisingReview website... More Info
Resort Reviews: World Class resorts... More Info
The Riffelalp Resort: Reviews on CruisingReview website... More Info
| CONTACT TEL: 608-238-6001 Email: greg@cruisingreview.com | RSS | AMP |