PDF Publication Title:
Text from PDF Page: 068
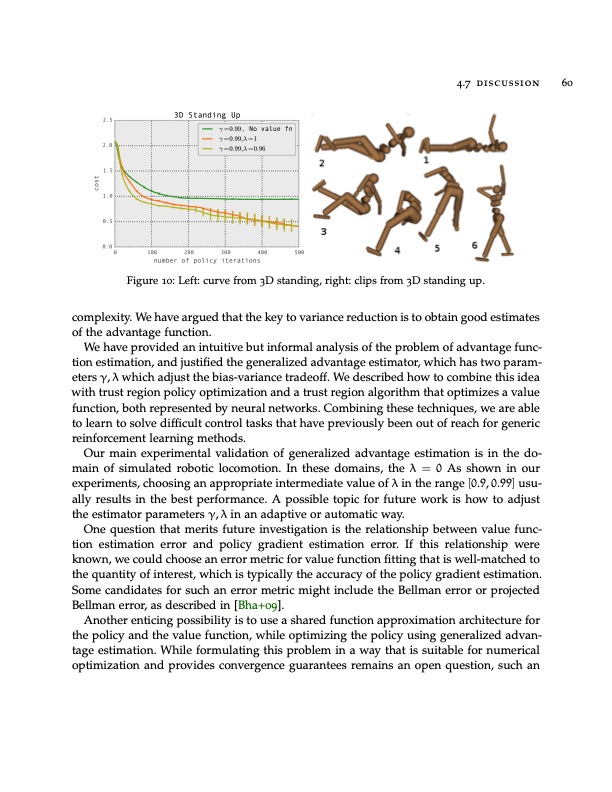
4.7 discussion 60 Figure 10: Left: curve from 3D standing, right: clips from 3D standing up. complexity. We have argued that the key to variance reduction is to obtain good estimates of the advantage function. We have provided an intuitive but informal analysis of the problem of advantage func- tion estimation, and justified the generalized advantage estimator, which has two param- eters γ, λ which adjust the bias-variance tradeoff. We described how to combine this idea with trust region policy optimization and a trust region algorithm that optimizes a value function, both represented by neural networks. Combining these techniques, we are able to learn to solve difficult control tasks that have previously been out of reach for generic reinforcement learning methods. Our main experimental validation of generalized advantage estimation is in the do- main of simulated robotic locomotion. In these domains, the λ = 0 As shown in our experiments, choosing an appropriate intermediate value of λ in the range [0.9, 0.99] usu- ally results in the best performance. A possible topic for future work is how to adjust the estimator parameters γ, λ in an adaptive or automatic way. One question that merits future investigation is the relationship between value func- tion estimation error and policy gradient estimation error. If this relationship were known, we could choose an error metric for value function fitting that is well-matched to the quantity of interest, which is typically the accuracy of the policy gradient estimation. Some candidates for such an error metric might include the Bellman error or projected Bellman error, as described in [Bha+09]. Another enticing possibility is to use a shared function approximation architecture for the policy and the value function, while optimizing the policy using generalized advan- tage estimation. While formulating this problem in a way that is suitable for numerical optimization and provides convergence guarantees remains an open question, such an 2.5 2.0 1.5 1.0 0.5 0.0 3D Standing Up γ =0.99, No value fn γ =0.99,λ =1 γ =0.99,λ =0.9 6 0 100 200 number of policy iterations 300 400 500 costPDF Image | OPTIMIZING EXPECTATIONS: FROM DEEP REINFORCEMENT LEARNING TO STOCHASTIC COMPUTATION GRAPHS
PDF Search Title:
OPTIMIZING EXPECTATIONS: FROM DEEP REINFORCEMENT LEARNING TO STOCHASTIC COMPUTATION GRAPHSOriginal File Name Searched:
thesis-optimizing-deep-learning.pdfDIY PDF Search: Google It | Yahoo | Bing
Cruise Ship Reviews | Luxury Resort | Jet | Yacht | and Travel Tech More Info
Cruising Review Topics and Articles More Info
Software based on Filemaker for the travel industry More Info
The Burgenstock Resort: Reviews on CruisingReview website... More Info
Resort Reviews: World Class resorts... More Info
The Riffelalp Resort: Reviews on CruisingReview website... More Info
| CONTACT TEL: 608-238-6001 Email: greg@cruisingreview.com | RSS | AMP |