PDF Publication Title:
Text from PDF Page: 011
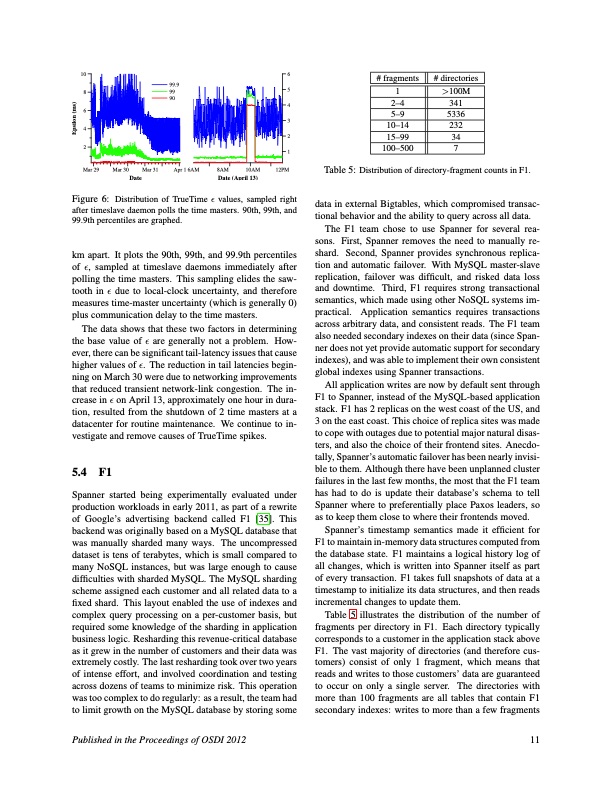
10 8 6 4 2 Mar 29 Mar 30 Mar 31 99.9 99 90 Apr 1 6AM 8AM 10AM 6 5 4 3 2 1 12PM # fragments # directories 1>100M 2–4 341 5–9 5336 10–14 232 15–99 34 100–500 7 Table 5: Distribution of directory-fragment counts in F1. data in external Bigtables, which compromised transac- tional behavior and the ability to query across all data. The F1 team chose to use Spanner for several rea- sons. First, Spanner removes the need to manually re- shard. Second, Spanner provides synchronous replica- tion and automatic failover. With MySQL master-slave replication, failover was difficult, and risked data loss and downtime. Third, F1 requires strong transactional semantics, which made using other NoSQL systems im- practical. Application semantics requires transactions across arbitrary data, and consistent reads. The F1 team also needed secondary indexes on their data (since Span- ner does not yet provide automatic support for secondary indexes), and was able to implement their own consistent global indexes using Spanner transactions. All application writes are now by default sent through F1 to Spanner, instead of the MySQL-based application stack. F1 has 2 replicas on the west coast of the US, and 3 on the east coast. This choice of replica sites was made to cope with outages due to potential major natural disas- ters, and also the choice of their frontend sites. Anecdo- tally, Spanner’s automatic failover has been nearly invisi- ble to them. Although there have been unplanned cluster failures in the last few months, the most that the F1 team has had to do is update their database’s schema to tell Spanner where to preferentially place Paxos leaders, so as to keep them close to where their frontends moved. Spanner’s timestamp semantics made it efficient for F1 to maintain in-memory data structures computed from the database state. F1 maintains a logical history log of all changes, which is written into Spanner itself as part of every transaction. F1 takes full snapshots of data at a timestamp to initialize its data structures, and then reads incremental changes to update them. Table 5 illustrates the distribution of the number of fragments per directory in F1. Each directory typically corresponds to a customer in the application stack above F1. The vast majority of directories (and therefore cus- tomers) consist of only 1 fragment, which means that reads and writes to those customers’ data are guaranteed to occur on only a single server. The directories with more than 100 fragments are all tables that contain F1 secondary indexes: writes to more than a few fragments Date Date (April 13) Figure 6: Distribution of TrueTime ε values, sampled right after timeslave daemon polls the time masters. 90th, 99th, and 99.9th percentiles are graphed. km apart. It plots the 90th, 99th, and 99.9th percentiles of ε, sampled at timeslave daemons immediately after polling the time masters. This sampling elides the saw- tooth in ε due to local-clock uncertainty, and therefore measures time-master uncertainty (which is generally 0) plus communication delay to the time masters. The data shows that these two factors in determining the base value of ε are generally not a problem. How- ever, there can be significant tail-latency issues that cause higher values of ε. The reduction in tail latencies begin- ning on March 30 were due to networking improvements that reduced transient network-link congestion. The in- crease in ε on April 13, approximately one hour in dura- tion, resulted from the shutdown of 2 time masters at a datacenter for routine maintenance. We continue to in- vestigate and remove causes of TrueTime spikes. 5.4 F1 Spanner started being experimentally evaluated under production workloads in early 2011, as part of a rewrite of Google’s advertising backend called F1 [35]. This backend was originally based on a MySQL database that was manually sharded many ways. The uncompressed dataset is tens of terabytes, which is small compared to many NoSQL instances, but was large enough to cause difficulties with sharded MySQL. The MySQL sharding scheme assigned each customer and all related data to a fixed shard. This layout enabled the use of indexes and complex query processing on a per-customer basis, but required some knowledge of the sharding in application business logic. Resharding this revenue-critical database as it grew in the number of customers and their data was extremely costly. The last resharding took over two years of intense effort, and involved coordination and testing across dozens of teams to minimize risk. This operation was too complex to do regularly: as a result, the team had to limit growth on the MySQL database by storing some Published in the Proceedings of OSDI 2012 11 Epsilon (ms)PDF Image | Google Globally-Distributed Database
PDF Search Title:
Google Globally-Distributed DatabaseOriginal File Name Searched:
spanner-osdi2012.pdfDIY PDF Search: Google It | Yahoo | Bing
Cruise Ship Reviews | Luxury Resort | Jet | Yacht | and Travel Tech More Info
Cruising Review Topics and Articles More Info
Software based on Filemaker for the travel industry More Info
The Burgenstock Resort: Reviews on CruisingReview website... More Info
Resort Reviews: World Class resorts... More Info
The Riffelalp Resort: Reviews on CruisingReview website... More Info
| CONTACT TEL: 608-238-6001 Email: greg@cruisingreview.com | RSS | AMP |